머신러닝
1. 머신러닝은 무엇인가?
머신러닝(machine learning)하면 떠오르는 빅데이터, 데이터마이닝, AI와의 개념적 차이를 알아보고 정리해보자.
a. 빅데이터와 머신러닝
빅데이터는 말 그대로 많은 데이터가 존재하는 것이며, 그 데이터들을 어떻게 잘 사용할 것/인가를 다루는 많은 방법론이 있다. 그 방법론들 중 요즘 가장 많이 사용되는 것이 머신러닝이다.
b. 데이터마이닝과 머신러닝
데이터마이닝은 정형데이터를 사용한다. 머신러닝의 경우 정형데이터도 사용이 가능하지만, 비정형데이터(텍스트, 이미지)를 분석하는 것으로 사용된다.
어떤 사람에 대한 정형데이터는 그사람의 나이 성별과 같은 정보가 테이블로 정리되어 있는 것을 생각하면 된다.
c. AI와 머신러닝
머신러닝은 AI의 일부분이며, AI는 말 그대로 사람의 지능을 어떻게 컴퓨터도 가지게 만들것인지를 의미한다. 사람처럼 지능적으로 만드는 방법에는 여러가지가 있지만 그중에서도 데이터에 의존하여 데이터를 통계적으로 분석하여 프로젝션 모델을 만드는 방법을 머신러닝이라한다.
d. 통계학과 머신러닝
통계학자들이 몇십년동안 만들어놓은 다양한 모델들을 가져다 실생활에서 볼 수 있는 다양한 데이터에 적용하는 것이 머신러닝이다.
통계학에서 다루는 데이터보다 훨씬 더 양이 많고, 노이즈 역시 많으며, 데이터가 부분적으로 훼손되거나 없는 데이터를 다룸으로써 통계학의 한계를 극복하는 것이 머신러닝이다. ( = expands the practical Limiations of Statistics )
2. 머신러닝에서 주로 다루는 문제(Major Problem Formulations in ML)
- 지도학습(Supervised Learning)
- 비지도학습(Unsupervised Learning)
- 강화학습
- Representaion learning
a. 지도학습(Supervised Learning)
정답을 가지고 있는 학습데이터로 학습을 하기 때문에 지도학습이라 불린다.
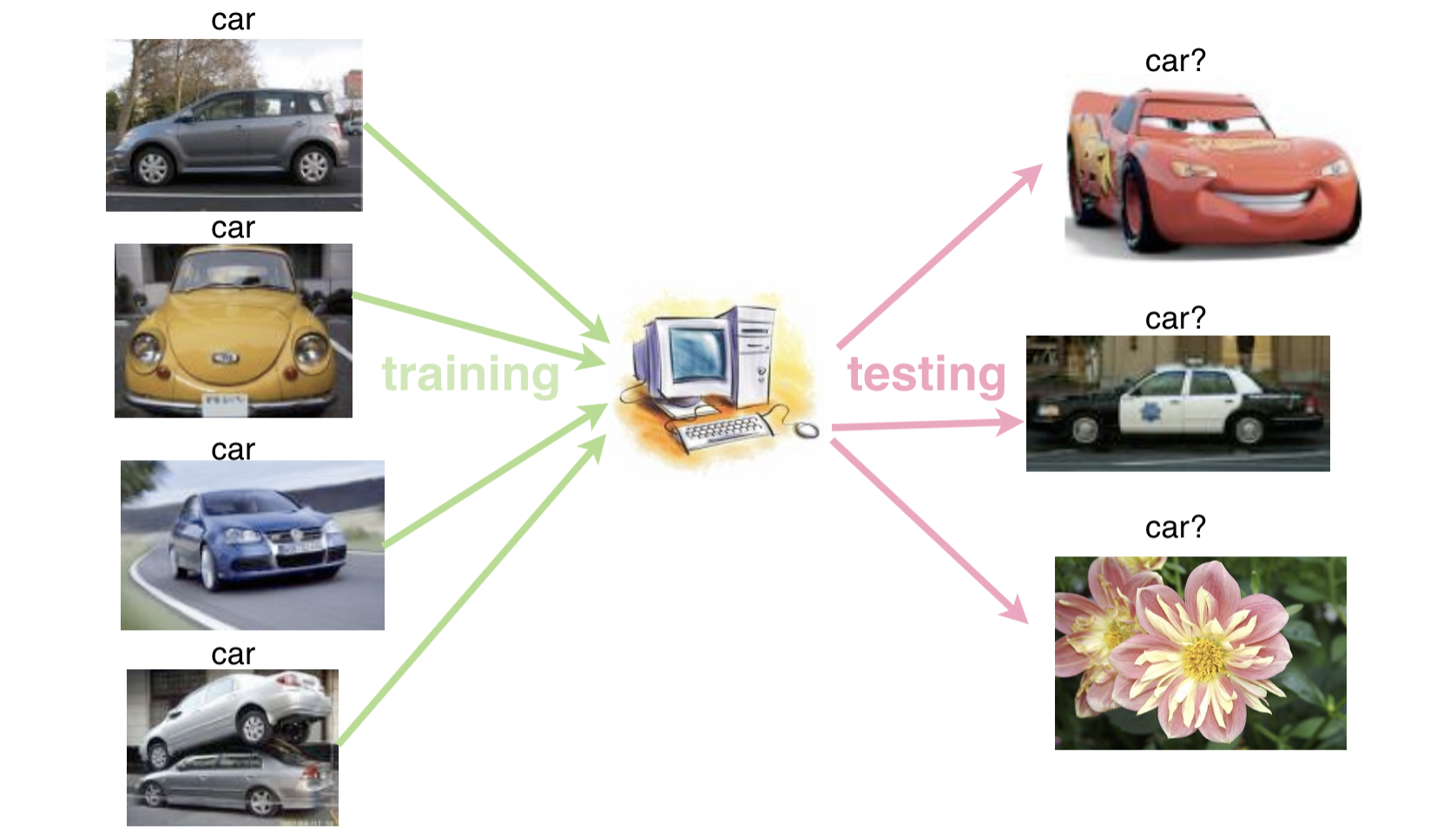
cat이라는 라벨을 붙인 고양이 사진과 dog라는 라벨이 붙은 강아지 사진이 학습데이터로 사용되며, 테스트데이터로 라벨이 붙지 않은 사진을 사용한다. 이때 분류(classification)가 잘 되는 경우 학습이 잘 되었다고 생각할 수 있다.
정답이 주어진 데이터를 구하는 것이 어려운 경우에는 지도학습을 하는 것이 불가능하다.
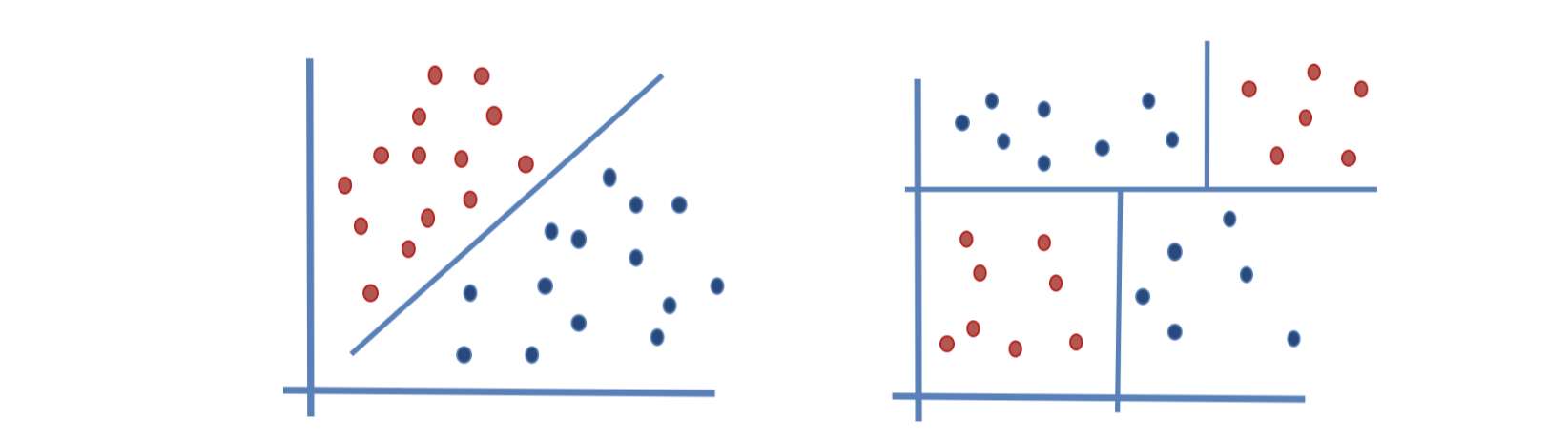
classification을 하는 방법으로는 선형 모델과 비선형 모델로 분류할 수 있다. 비선형 모델은 y축에 대해 질문을 하고 y < a 와 y >= a로 나눠 분류하게 된다. 계속해서 질문을 던져 해당 데이터가 어떤 값으로 분류되는지(어떤 영역에 속할지)를 결정하게 된다.
b. 비지도학습(Unsupervised Learning)

사람이 하는 학습이 여기에 속한다. 위와 같은 사진을 주고 비슷한 것들을 찾으라고 하는 것을 의미한다.
비지도 학습에서는 가까이 있는 사물들은 같은 그룹에 속할 것이라는 가정을 가지고 사람이든 사물이든 몇 개의 그룹으로 나눌 것인가?가 중요한 결정요인이 된다.
그룹은 어떻게 나누게 되는가?
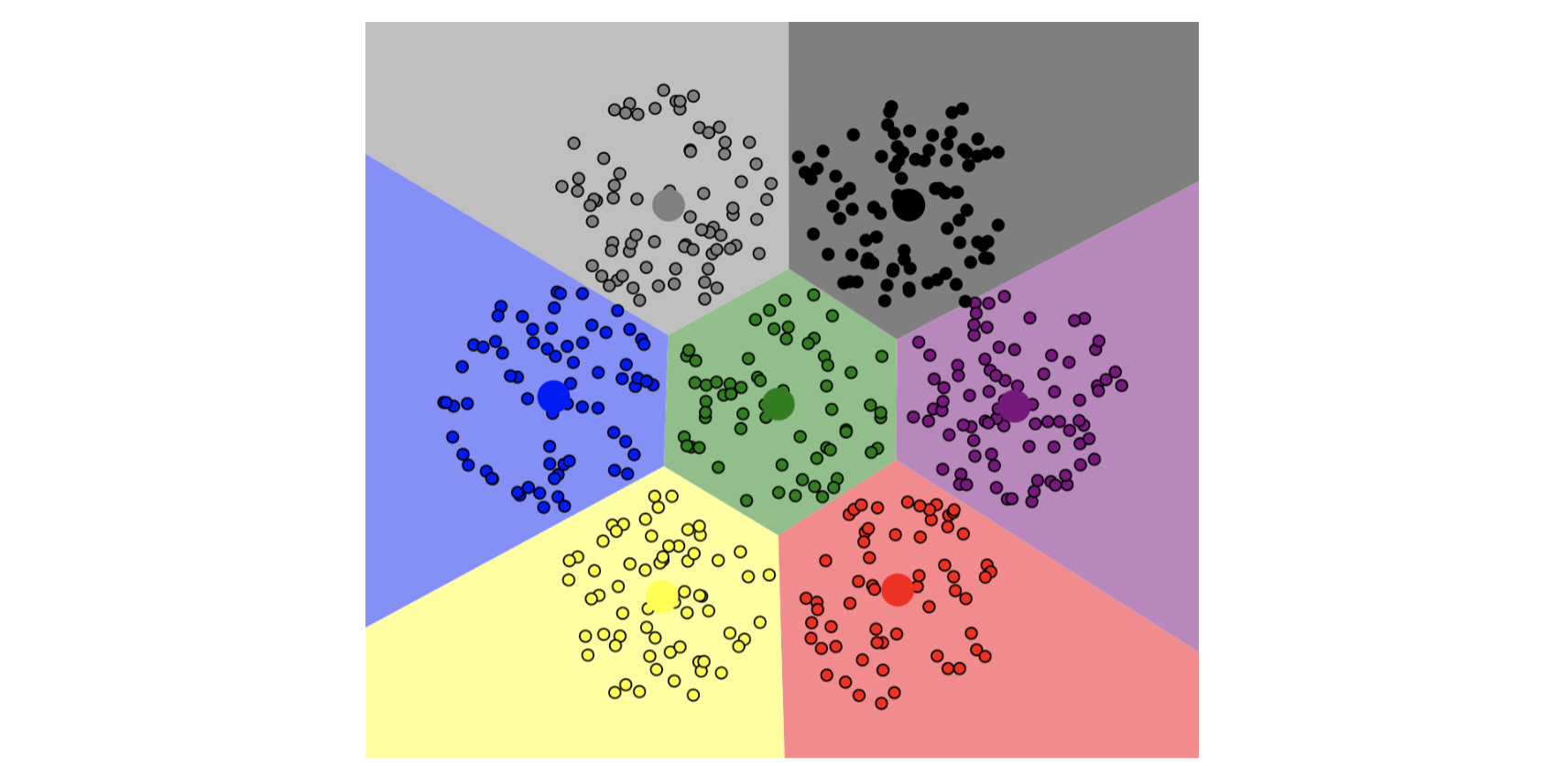
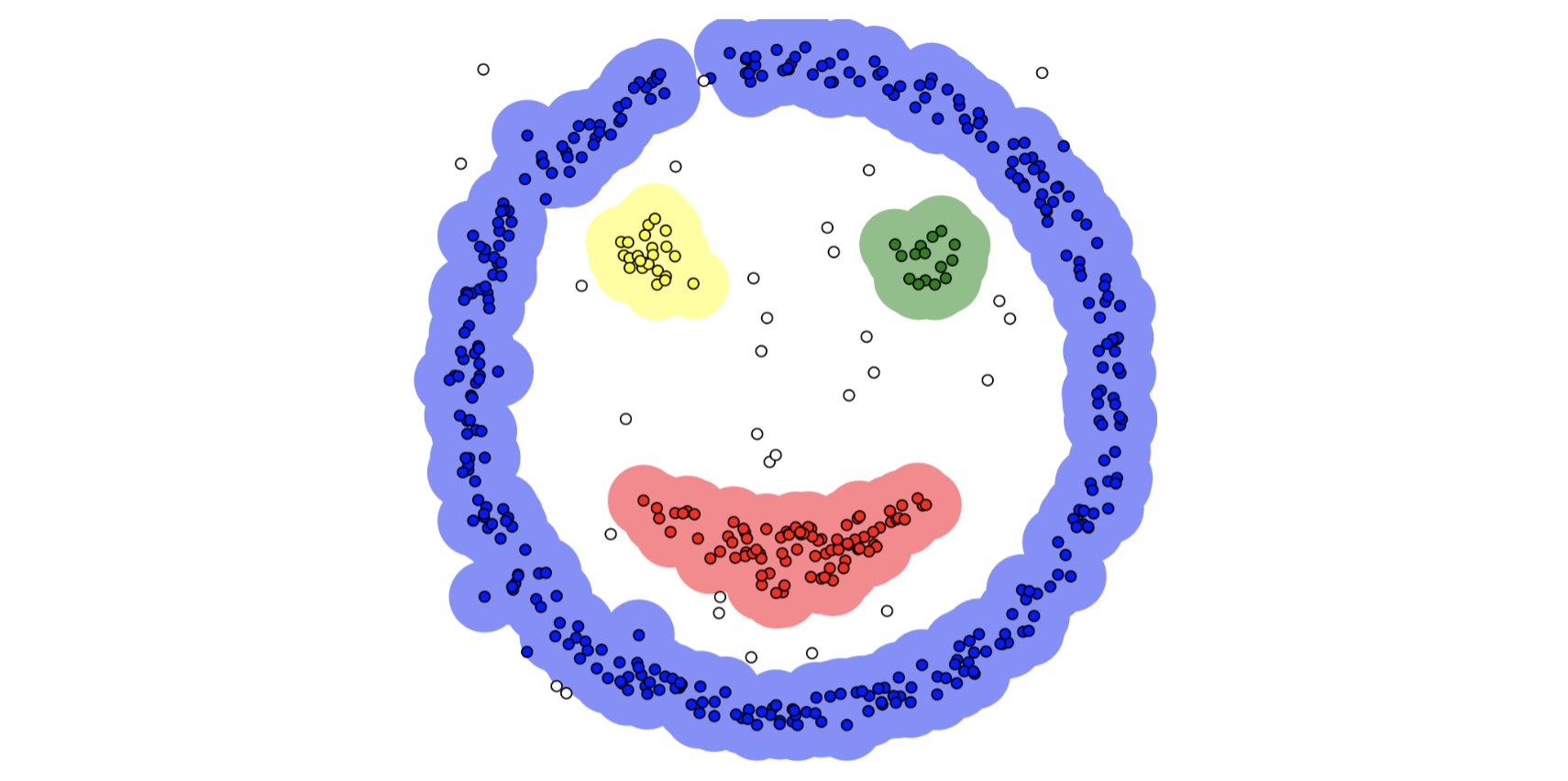
지도학습, 비지도학습 모두 ‘내가 가지고 있는 데이터의 숨겨진 의미(그룹화)를 가장 잘 나타낼 수 있는 모델은 무엇일까?’가 주된 학습의 요인이다.
c. Representaion Learning
- Deep Neural Networks
- 데이터의 사이즈가 커짐으로 인해, 의미가 있는 데이터는 남겨두고 의미가 없는 데이터는 줄이는 것을 Neural Networks를 사용하면 가능하다. ( = Reducing the Dimesionality of Data with Neural Networks)
- Facial Recognition
- Layer 1 : 각 픽셀에 대한 색상
- Layer 2 : 각 픽셀을 연결하여 line과 curve (색상의 대조가 큰 부분)찾기
- Layer 3 : 2에서 찾은 곡선을 이용하여 눈과 코, 얼굴을 찾아낸다.
3. AI의 응용분야와 데이터셋(Major Domains within AI and Corresponding Datasets)
a. Visual Intelligence
- MINIST : 숫자필기인식
- ImageNet : 몇천개의 클래스의 이미지가 존재
b. Language intelligence
- SQuAD Dataset : 질문에 대한 답이 가능한가?
c. Machine Translation
- Europarl Corous : 번역
- GLUE Benchmark : 구체적인 언어에 대한 테스트가 가능한 데이터셋
- 이 문장이 문법적으로 올바른가?
- 이 문장에서 주장하는 것?