Linear Regression이란, x값이 주어졌을때 y값을 잘 예측할 수 있도록 수학적으로 데이터에 가장 접합한 라인을 그려주는 것이다.
Linear Regression
classification이 값에 따라 클래스 분류를 하는 것이라면, Linear Regression는 값을 내주는 것이다.
Linear Regression이란, x값이 주어졌을때 y값을 잘 예측할 수 있도록 수학적으로 데이터에 가장 접합한 라인을 그려주는 것이다.
a. Polynomial Regression
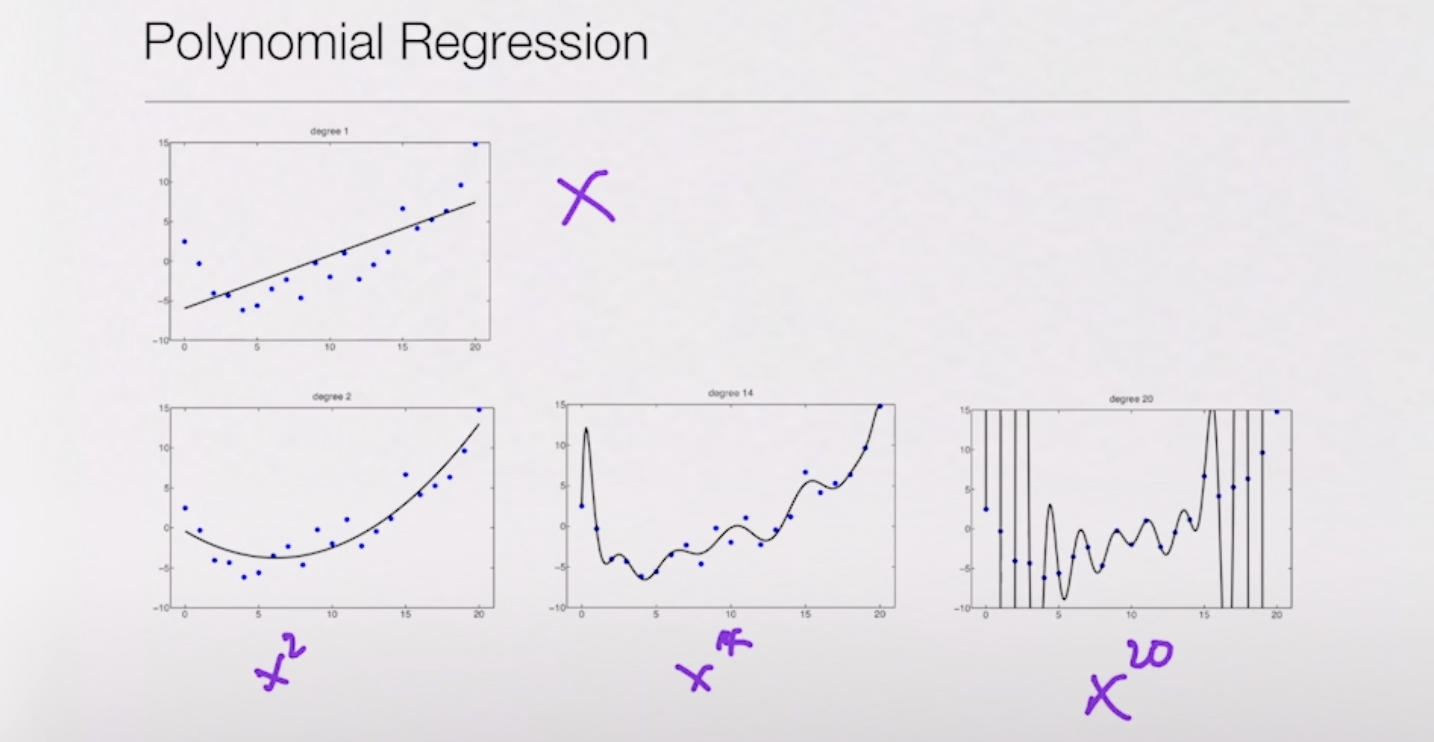 Polynomial Regression을 사용하게 되면 x^2가 데이터를 가장 잘 설명할 것 같지만 사실은 x^20이 데이터를 더 잘 설명하는 라인임을 확인 할 수 있다.
Polynomial Regression을 사용하게 되면 x^2가 데이터를 가장 잘 설명할 것 같지만 사실은 x^20이 데이터를 더 잘 설명하는 라인임을 확인 할 수 있다.
b. RSS (Residual Sum of Squence)
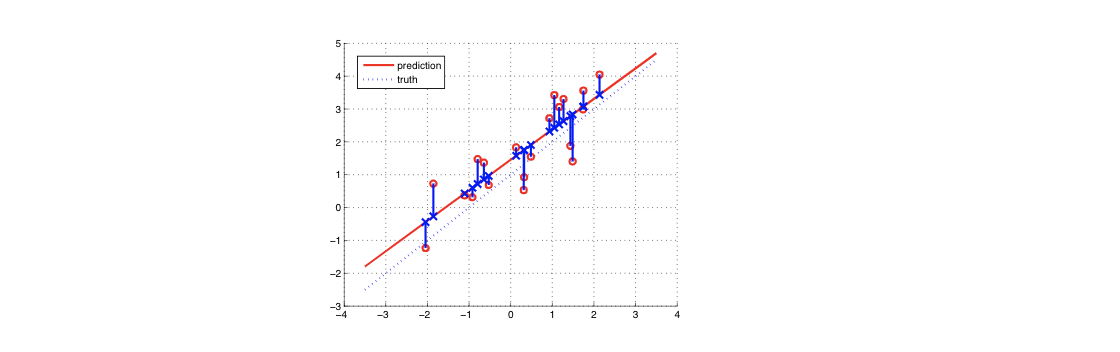
우리가 어떤 선을 구했을때, 실제 데이터와의 차이를 통해 더 적합한 선을 찾아내는 것
c. Ridge Regression = Regularization
- overfiting : for linear regression, this means the weight can become large
- underfitting : 오버피팅과 반대로 데이터가 너무 적거나 학습이 제대로 이루어지지 않아 Decision Boundary에 근접하지 못한 상태를 말한다.
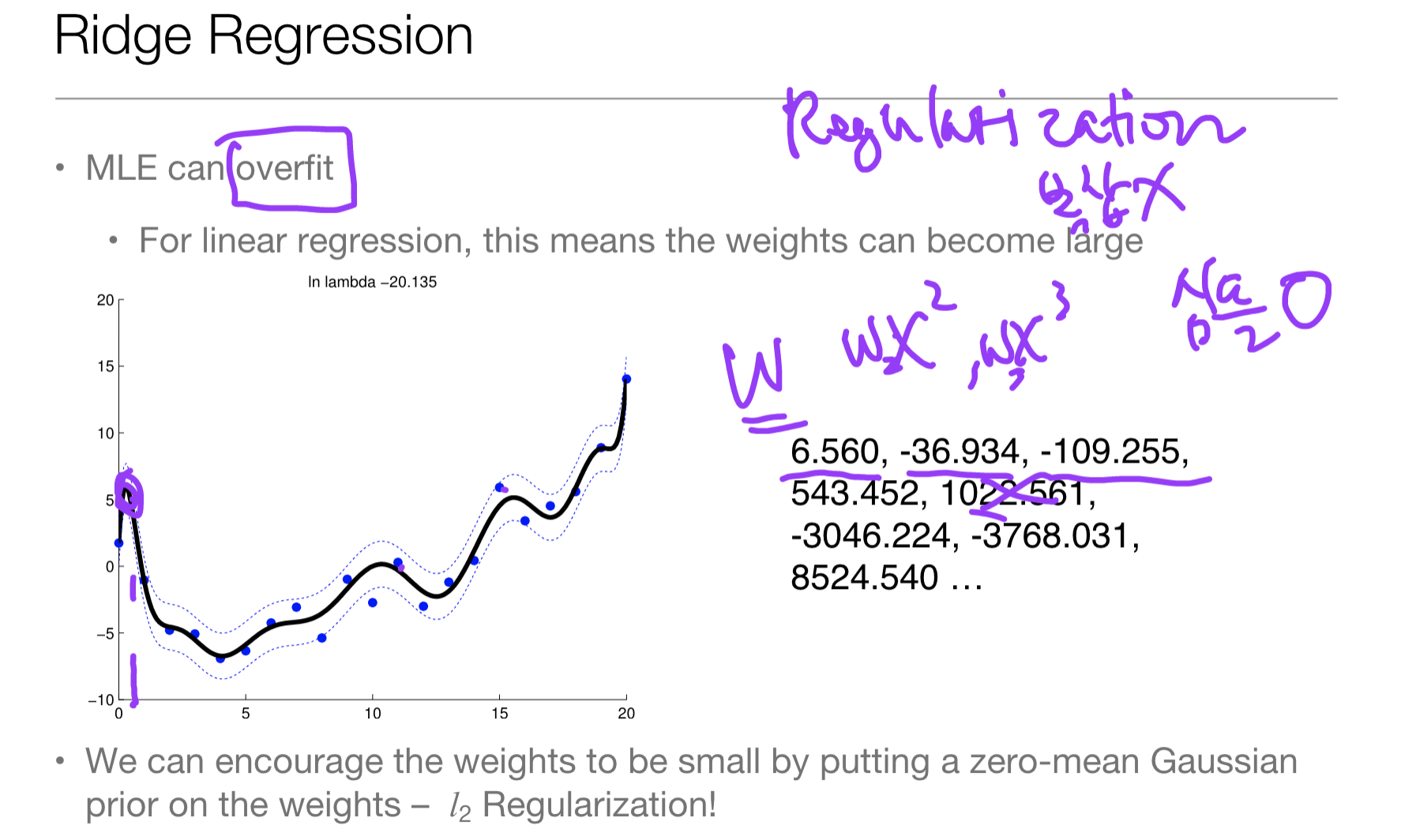
Ridge Regression이란, 너무 큰 w 값(overfit)은 regression에서는 모델이 복잡해지므로 좋지 않다. 그러므로 큰 값에 대해 패널티를 부여하는 방식으로 해결하는 것을 말한다. 즉, overfit을 완화시켜 준다.
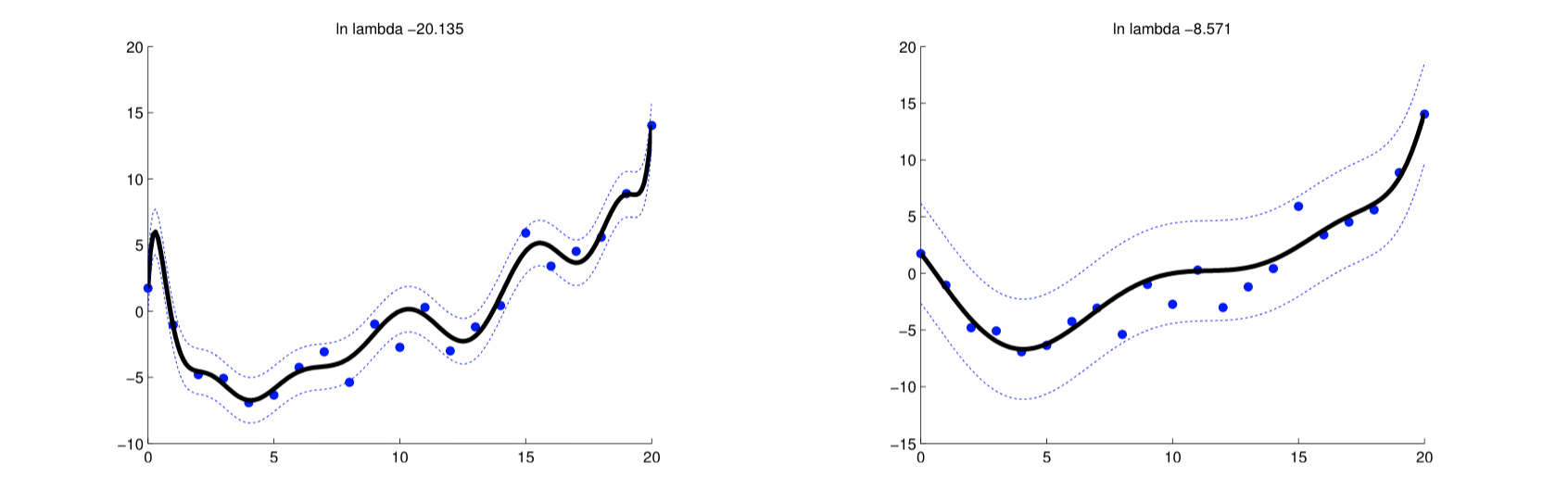
[좌] Regularization 적용 전, [우] Regularization 적용 후
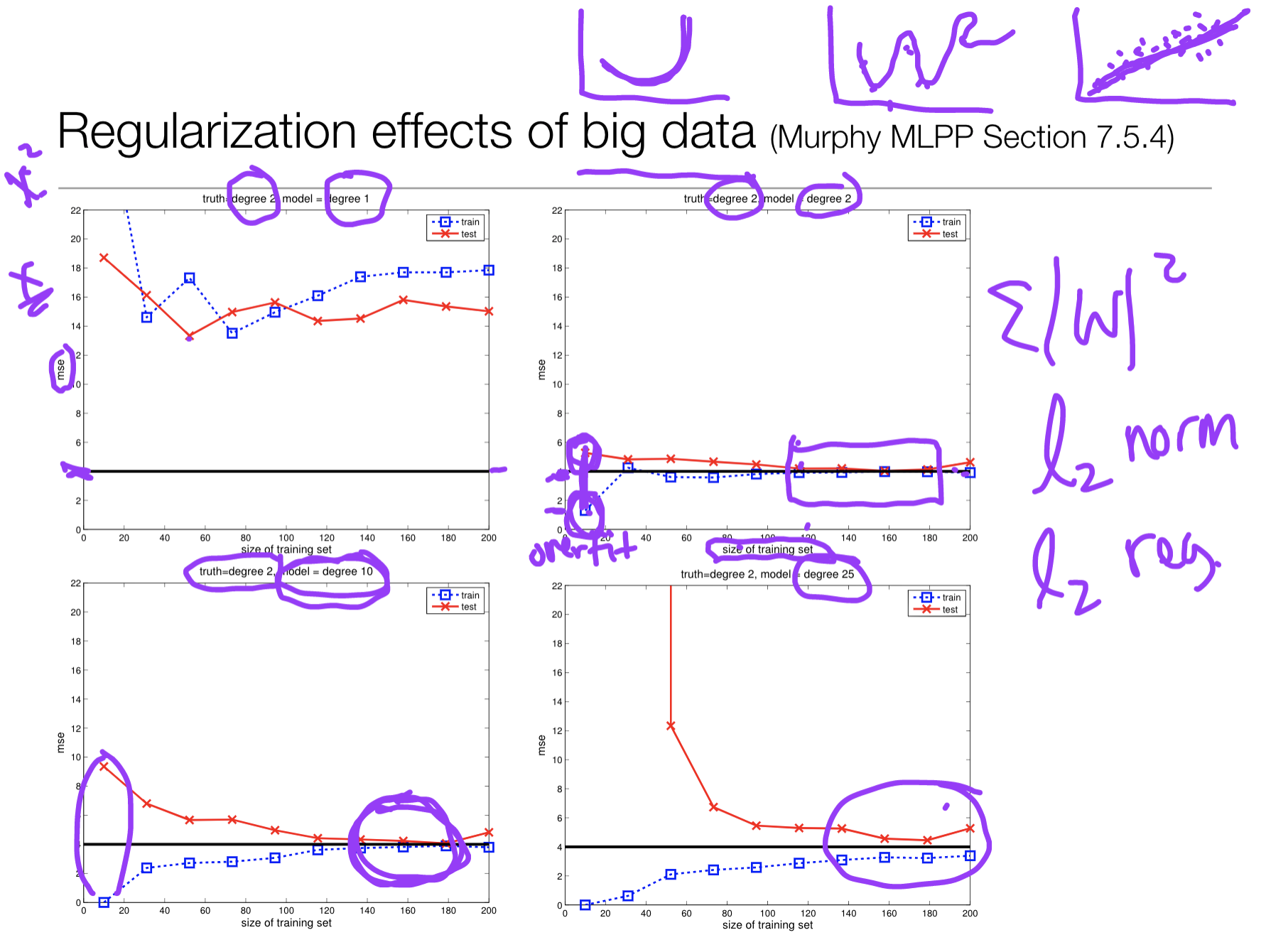
Regularization effects of big data
[검]-이상적인 에러, [파]-트레이닝데이터 에러, [빨]-테스트데이터 에러
x축이 커질수록 이상적인 값이 나오고 있다. 즉, 데이터가 많은 경우 좀 더 심플한 라인을 만들 수 있다.